Definition of speech to text for Podcasting technology
Speech to text for Podcasting technology, also known as speech recognition or voice recognition, is a type of software that uses artificial intelligence (AI) to transcribe spoken words into written text. This technology can be used in a variety of applications, such as dictation, voice commands, and transcription of audio or video recordings. The Speech to Text for podcasting works by analyzing the sound waves of speech and comparing them to a database of pre-recorded words and phrases to generate a written transcript.
Explanation of why transcribing podcast audio into text is important
Speech to Text for Podcasting: The Key to Making Your Podcast More Accessible, Engaging, and Valuable
Transcribing your podcast audio into text has numerous benefits, especially when utilizing speech to text technology. Here are a few key ways speech to text for podcasting can enhance the podcast experience:
- Improved Accessibility: With speech to text, your podcast becomes more accessible to a wider audience, including those with hearing impairments or those who speak different languages. This can help increase your podcast’s reach and inclusivity.
- Enhanced Note-Taking and Follow-Along: A written transcript makes it easier for listeners to follow along and take notes, improving their understanding and retention of the information presented.
- Increased Searchability: Transcribing your podcast with speech to text technology makes the content more searchable, boosting the visibility of your podcast and making it easier for new listeners to find.
- Increased Shareability: The transcript can be shared on social media, in blogs, and on other platforms, increasing the reach of your podcast.
- Improved Indexing: A transcript can improve indexing on search engines, making it easier for potential listeners to find your podcast.
- Enhanced Engagement: Allowing listeners to read along with the conversation can make the content more engaging and interactive.
- Better SEO: Search engines can index the text, improving the SEO of your podcast and making it easier for people to find through search results.
Preparing Your Audio Content for Transcription using Speech to Text Podcasting
Tips for cleaning up background noise and adjusting volume
Here are some tips for cleaning up background noise and adjusting volume when preparing your audio content for transcription:
- Step-1: Use a noise reduction software: There are several noise reduction software options available that can help to remove background noise from audio recordings. Some popular options like Audacity, Adobe Audition, and Izotope RX.
- Step-2: Isolate the audio: If possible, try to record your audio in a quiet room or use a noise-canceling microphone to reduce background noise.
- Step-3: Use EQ: Use an equalization software to remove unwanted frequency ranges.
- Step-4: Normalize the audio: Use a normalization software to adjust the volume level of the audio so that it is consistent throughout the recording.
- Step-5: Trim the audio: Use an audio editing software to trim any unnecessary or irrelevant parts of the audio recording.
- Step-6: Use the built-in noise reduction feature: Some transcription software has built-in noise reduction feature which can help to remove background noise before transcription.
Importance of breaking up the audio into smaller segments
The rise of AI speech to text converters online has revolutionized the way podcasting content is transcribed and translated. The use of speech to text for podcasting has made the transcription process more efficient and accurate. By breaking up audio into smaller segments, the transcription software can concentrate on a smaller amount of audio, resulting in improved accuracy and an easier editing process. Moreover, breaking up audio into segments also enhances the user experience by allowing listeners to easily navigate to the relevant content they seek.
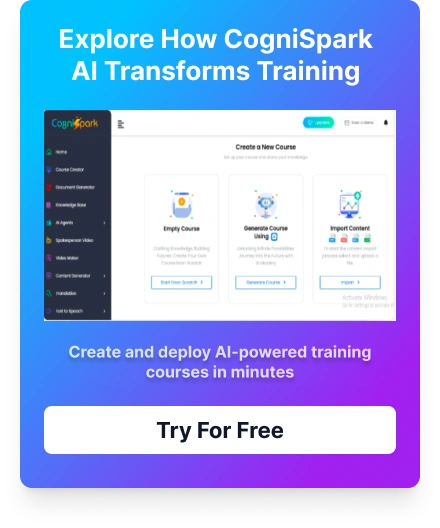
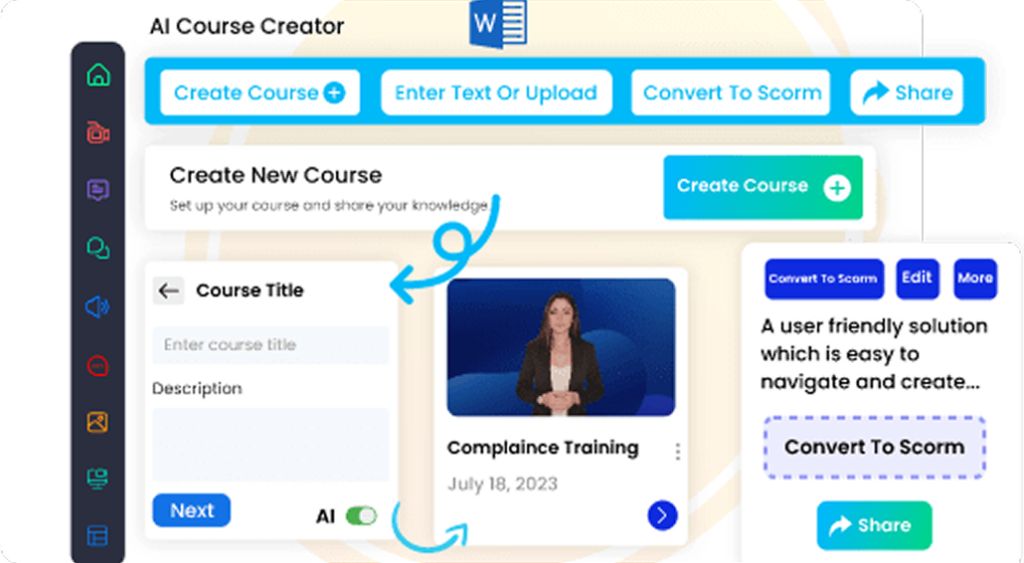
CogniSpark offers a unique speech to text for podcasting service, incorporating artificial intelligence and machine learning technology to deliver clear and accurate transcriptions of audio recordings. The company boasts of its ability to transcribe a variety of accents, dialects, and languages, making it a useful tool for businesses and organizations operating in different countries. Another standout feature of CogniSpark’s speech to text podcasting service is its ability to remove background noise and other interruptions from the audio recording, resulting in a clearer and more readable final product.
In conclusion, speech to text podcasting technology has dramatically transformed the podcasting industry and is proving to be an essential tool for businesses and educators looking to improve their content and reach a wider audience. As technology continues to advance, we can expect to see even more improvements in the accuracy, efficiency, and accessibility of speech to text podcasting conversion and foreign language translations, ultimately leading to better cross-cultural communication and collaboration.
Recording Your Podcast
Importance of using a high-quality microphone
using a high-quality microphone is crucial when translate with British accent, especially when using speech to text for podcasting technology. A high-quality microphone can help to capture clear and crisp audio, reduce background noise and other interference, and improve the overall quality of the audio recording. This can lead to more accurate transcriptions and a better user experience for the listener.
Tips for speaking clearly and at a consistent pace
When speaking clearly and at a consistent pace is crucial when recording audio for transcription with speech to text for podcasting technology. Here are some tips to help improve the clarity and consistency of your speech
- Speak clearly and enunciate: This means pronouncing words clearly and distinctly, making sure that all sounds are pronounced as intended. Avoid mumbling or slurring words.
- Speak at a natural pace: Speak at a pace that is comfortable for you, but try to avoid speaking too quickly or too slowly. A consistent pace will make it easier for the speech-to-text software to understand and transcribe your words accurately.
- Use proper volume: Speak at a volume that is appropriate for your recording environment. Speak loud enough to be heard clearly, but not so loud that you are overdriving your microphone.
- Speak in a quiet environment: Record in a quiet and well-insulated room to minimize background noise and other interference.
- Avoid filler words and phrases: Try to eliminate filler words and phrases such as “um,” “ah,” and “like” from your speech, as they can make your speech less clear and more difficult to transcribe.
- Pause before and after changes in topic: Pause before and after changes in topic: It’s important to pause before and after changing topic, this will help the AI speech to text converter online to understand the context and the flow of the conversation
Proofreading and Editing the Transcript
Importance of reviewing the transcript for errors
Reviewing the transcript for errors is an important step in the transcription process when using speech to text for podcasting technology. It helps to identify and correct errors, improve the overall accuracy and readability of the final product, and ensure that sensitive information is kept private. Reviewing the transcript can also help to improve the overall quality of the audio recording by providing feedback to the speaker on how to improve their speaking style. It is important to take the time to review the transcript to ensure that it is accurate and free of errors.
Tips for editing and polishing the final product
Here are some tips for editing and polishing the final product:
- Review the transcript for errors: Check for consistency: Make sure that the transcript is consistent in terms of formatting, punctuation, and capitalization.
- Check for readability: Ensure that the transcript is easy to read and understand by checking for long sentences, complex vocabulary, and unclear phrasing.
- Edit for style: Edit the transcript for style, tone and readability that suits the target audience and medium where it will be used.
- Add additional information: Add information such as speaker IDs, timestamps, and other contextual information that can help to improve the overall understanding of the transcript.
- Check for sensitive information: Make sure that the transcript does not contain any sensitive or private information.
Choosing the Right Transcription Software
Factors to consider when choosing a Speech to Text podcasting software
When choosing a transcription software, there are several factors to consider, including:
- Accuracy: The most important factor to consider when choosing an AI speech to text converter online software is the accuracy of the transcriptions. The software should be able to produce accurate and reliable transcriptions, even with different accents, multiple speakers and background noise.
- User-friendliness: Another important factor to consider is the user-friendliness of the software. The software should be easy to navigate and use, with a user-friendly interface that makes it easy to upload audio or video files, transcribe them, and export the transcript.
- Number of languages supported: If you are planning to transcribe audio or video in multiple languages, it is essential to check the number of languages the software supports.
- Real-time transcription: Some software offers real-time transcription, which can be useful if you need to transcribe live events, meetings or interviews.
- Cost: The cost of the software should also be considered. Some software is free, while others require a subscription. It’s important to consider the budget and the cost of the software in relation to the value it will provide for your podcast.
- Customer support: Consider if the software has a good customer support service in case you face any technical issues or have any questions.
Comparison of different language translator options.
There are several transcription software options available, each with their own features and capabilities. Here is a comparison of four popular options:
It is a transcription software that uses AI Speech to text convertor online to transcribe audio and video recordings in multiple languages. It can handle multiple speakers and different accents, and offers high accuracy in its transcriptions. Some of the key features of CogniSpark include:
- Automatic punctuation: It uses advanced AI algorithms to add punctuation to the transcript, making it easier to read and understand.
- Speaker identification: CogniSpark can identify and label different speakers in the transcript, making it easier to follow along and understand who is speaking.
- Export options: You can export transcripts in various formats, such as Microsoft Word, PDF, and plain text, making it easy to share and publish the transcript.
- Multi-language support: It has different languages, which can be useful for podcasts that have guests speaking in different languages.
- Integration: It can be integrated with various platforms, such as Zoom, Microsoft Teams, and Slack, making it easy to transcribe meetings and conference calls.
- Pay-as-you-go pricing: A pay-as-you-go pricing model makes it easy to pay for only the transcription that you need.
- Cloud-based: It is cloud-based, which means it can be accessed from anywhere and does not require any additional hardware or software installation.
This software uses AI to transcribe audio and video recordings in real-time. It offers high accuracy and can transcribe multiple speakers at once. It also offers a range of features such as automatic punctuation, foreign language translations, speaker identification, and the ability to export to various formats such as Microsoft Word and PDF. Otter.ai also has a free version and a paid version with more features.
This software uses AI Speech to text convertor online to transcribe audio and video recordings and can handle multiple speakers and different accents. It offers high accuracy and can export transcripts in various formats. Temi also offers a transcription editor to make editing and polishing the transcript easier. Temi has a pay-as-you-go pricing model.
This software uses AI speech to text convertor online to transcribe audio and video recordings and can handle multiple speakers and different accents. It offers high accuracy, and a unique feature is the ability to edit and collaborate on the transcript in real-time. Trint also has a pay-as-you-go pricing model.
Final Thoughts
In conclusion, speech to text podcasting technology is an efficient and cost-effective way to transcribe podcasts. With the advances in AI technology, speech-to-text software is becoming more accurate and reliable than ever before. It can help to make your podcast more accessible and widely shared by providing transcriptions that can be used for different platforms and purposes.
speech to text podcasting technology using AI is a powerful tool that can help to improve the accessibility and reach of your podcast. We encourage you to try it out and see the benefits it can bring to your podcast production.